

[P14] Tabular foundation models - comparing TabPFN, TabICL and supervised ML models (getting started)
Getting started with TabICLv2

This post continues my series on tabular foundation models. So far, I have covered the basic vocabulary of tabular foundation models in P3, the posterior predictive distribution in P4, the architecture in P5, pre-training in P6, the TabPFN repository in P7, the hands-on demo’s classification and regression examples in P8, TabPFN Client in P9, TabPFN embeddings in P10, TabPFN’s predictive behavior in P11, time series forecasting with TabPFN in P12, and using TabPFN for causal inference in P13.
For a new reader, the minimum background is this: TabPFN is a pretrained tabular foundation model. Unlike XGBoost or Random Forest, its ordinary .fit() call does not update model weights to learn a fresh model from scratch. Instead, .fit() prepares the labelled rows as context for the current task, and TabPFN uses that context to predict new rows. That is why I have described TabPFN as a context-conditioned predictor throughout this series.
In previous posts, I completed the examples given in TabPFN’s hands-on demo notebook, except for unsupervised learning, which I left out intentionally. Today, I moved on to TabICLv2, which is a different tabular foundational model. I chose TabICLv2 because it’s almost as good as TabPFN and is free and open source, whereas TabPFN requires commercial license.
TabICLv2’s GitHub repository contains examples that demonstrate its usability, but there’s no comprehensive Jupyter notebook like that of TabPFN, and I felt that the examples are also basic. To test TabICLv2 and compare it with TabPFN, I felt that I first needed to develop a test bench. In this post, I am sharing with you the Jupyter notebook I created for this purpose. It contains the TabPFN-related code from my previous posts and the TabICL-related code from their GH repo. You can find the notebook here in my GitHub repo.
Using the Notebook
To use the notebook, you can download it from my GH repo and run it in Kaggle. Once you open Kaggle, - you can create a notebook as follows,
and import my notebook.
Make sure to use the GPU because both TabPFN and TabICL are extremely slow on the CPU.
Once you have the setup ready, you would need Prior Labs' API token to download the weights of TabPFN and Hugging Face access token (optional) to download TabICL. You can specify them in Kaggle secrets, and they will be imported automatically when the notebook runs.
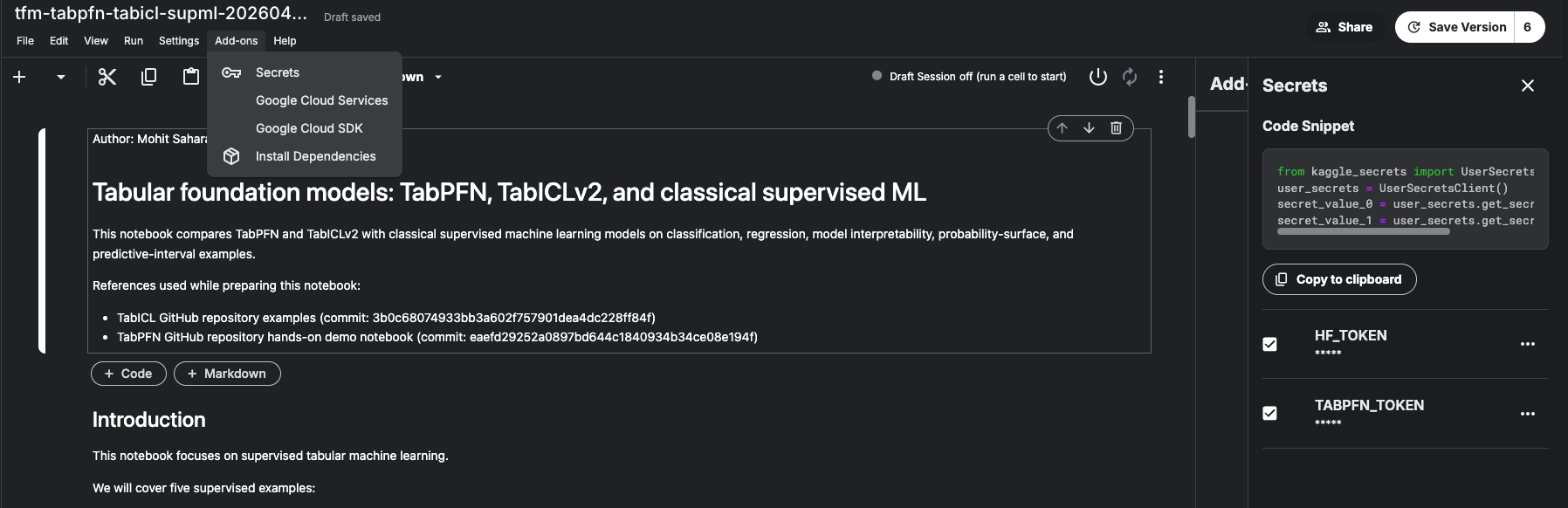
The secrets are always available on Kaggle (privately, only to you). So once you set them, you can always import any notebook I share on GitHub and use it immediately with your secrets.
Contents

The first four sections (0-3) of the notebook contain the code from my previous posts. I felt that the examples given in the TabICL repository were not as good as the ones I looked at in previous posts. Since I had already worked on making the classification, regression, and model interpretability (SHAP and embeddings) examples work in previous posts, I thought I would use them here and include TabICL instead of reinventing new examples. So that’s what I did.
The examples in section 4 and 5 are taken from the TabICL repository. For now, I only added them to the notebook and made them work. I wi…ll look into the details in future posts.
Classification and Regression
The following figures show the comparison of all the models for classification and regression tasks. I verified that the performance of TabPFN and other classical ML models is consistent with previous blog posts. TabICL shows improvement compared to TabPFN, but the difference is statistically insignificant. However, please keep in mind that this (and other observations mentioned below) is a preliminary observation, and I could have a closer look in future posts.
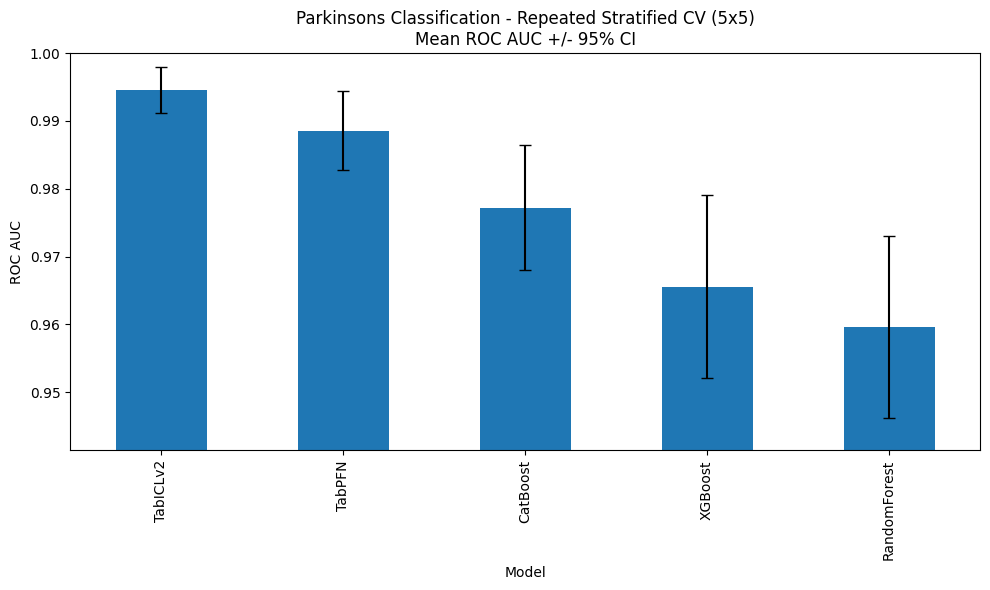
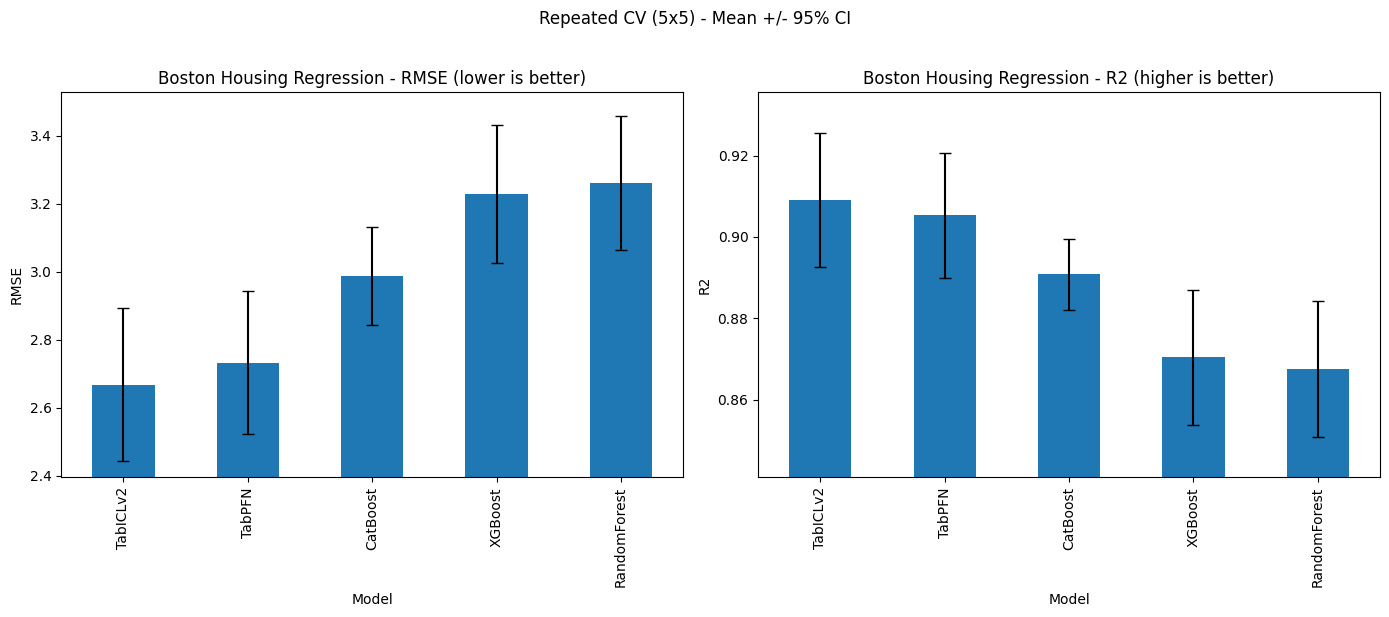
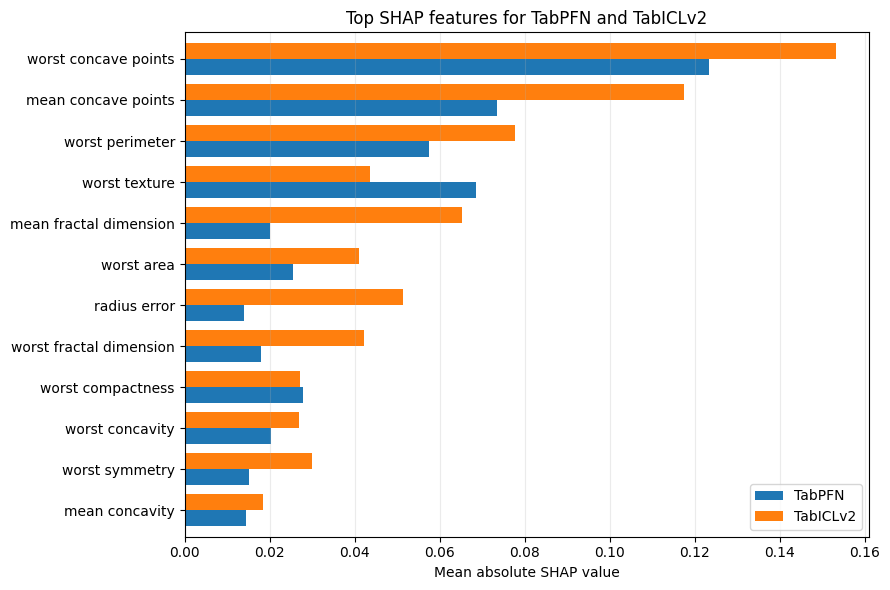
Model Interpretability: SHAP and Embeddings
For now, I think there’s no need to comment on the SHAP plot other than the fact that this plot is in a different format than previous blog posts to enable the side-by-side comparison. I could look into it in future posts, but I don’t think SHAP is a priority, for now, because I am currently more interested in developing a holistic picture of tabular foundation models rather than digging deep into one topic.
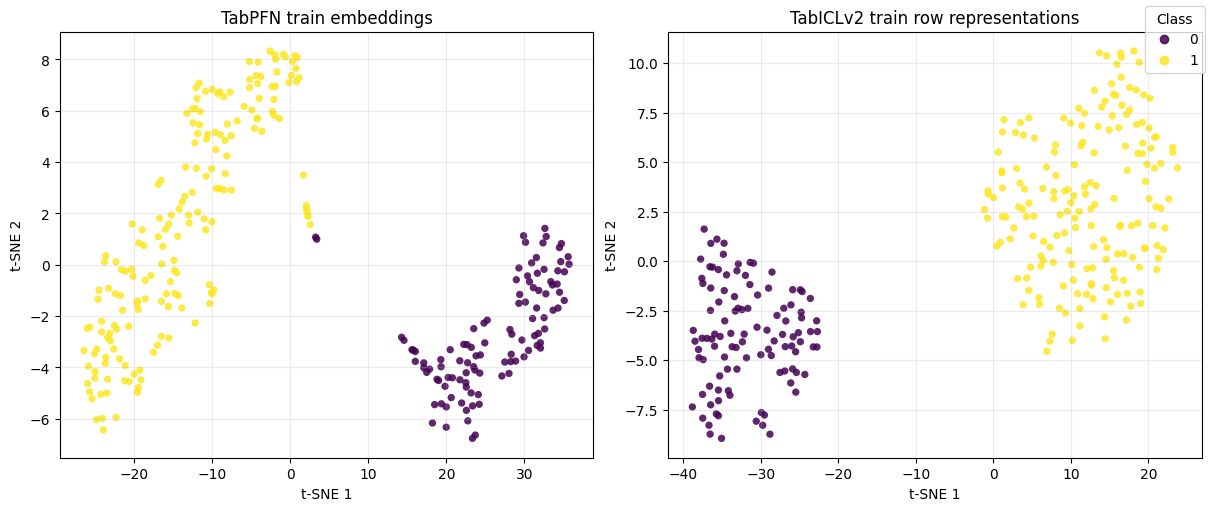
The embeddings section highlighted an important point. While TabPFN exposes embeddings through TabPFNEmbedding, TabICLv2 does not currently expose the same public embedding API. However, it can cache row representations when kv_cache="repr" is used, and that was used to produce the comparison shown below.
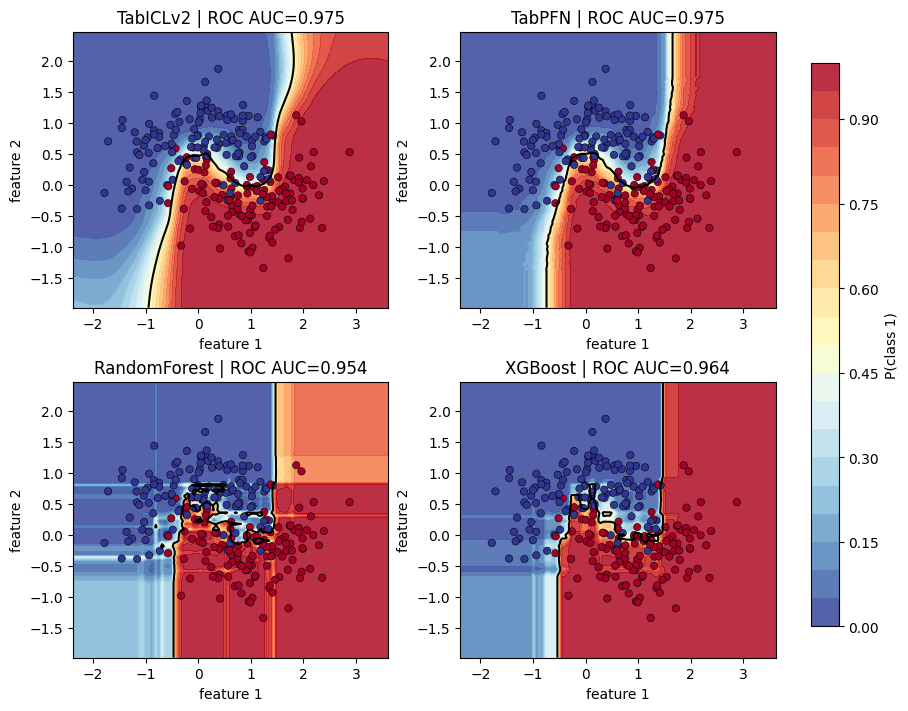
Probability Surfaces
The following figure shows how each classifier distributes class probability across a noisy two-dimensional input space. The point is not to ask which model has the best score, but how each model behaves between observed training points. For now, I won’t go into the details and leave them for future posts.
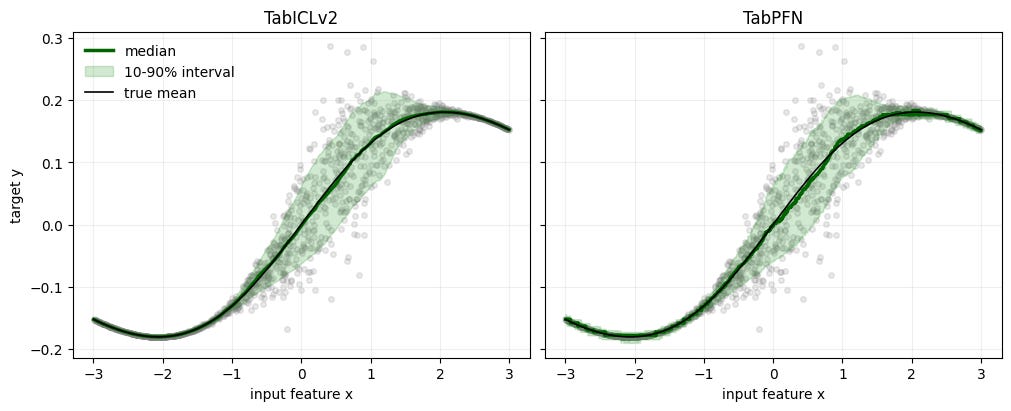
Quantile Regression
The following figure shows the comparison of predictive intervals on a regression problem. Again, I will discuss the details in future post.
Closing Thoughts
With this post, this series has moved on from using only TabPFN to comparing TabPFN and TabICL. Today, I only shared the code and output. I will go deeper in comparing TabPFN and TabICL in future posts. In the meantime, I encourage you to play with the notebook. If you do, let me know in the comments what you think of these models and the modifications you made.