

[P21] Tactical asset allocation with TabPFN, TabICL, and XGBoost - 2
Given information available at a monthly signal date, can TabPFN, TabICL, XGBoost, and simple allocation rules rank assets in a public ETF universe by next-month relative attractiveness?

In P20, I converted tactical asset allocation into a supervised tabular ranking problem. Each row was an asset-month observation, the label indicated whether that asset landed in the next-month top group, and TabPFN, TabICL, XGBoost, and deterministic allocation rules were evaluated as allocation scorers rather than price forecasters.
That first version was intentionally controlled. It used a nine-ETF universe, a top-three target, ticker identity features, a close-to-close return convention, and a simple transaction-cost-aware portfolio diagnostic. The result was useful, but the limitations were also clear. A nine-asset universe makes the top-group label coarse. Static ticker identity can make the model learn persistent ETF identity rather than reusable market-state relationships. Close-to-close evaluation is easy to audit, but it is not the same as asking what would happen if a signal were acted on after month-end information is available. The portfolio diagnostic also needed more stress checks.
This post is the follow-up. I keep the same supervised tabular framing, but I make the allocation testbench more demanding in the directions that mattered most after P20:
The universe is expanded from 9 ETFs to 25 ETFs.
The target changes from top 3 of 9 to top 5 of 25.
The base positive rate falls from about 0.333 to about 0.200.
The target return convention changes from close-to-close to next-open-to-next-open.
The main feature set removes ticker identity, asset-group metadata, and risk-bucket metadata.
Feature-set sensitivity is checked with lightweight Logistic Regression diagnostics.
The notebook adds multi-horizon and benchmark-relative audits.
The portfolio section adds turnover, tax-drag, drawdown, benchmark-relative, and constrained-weight diagnostics.
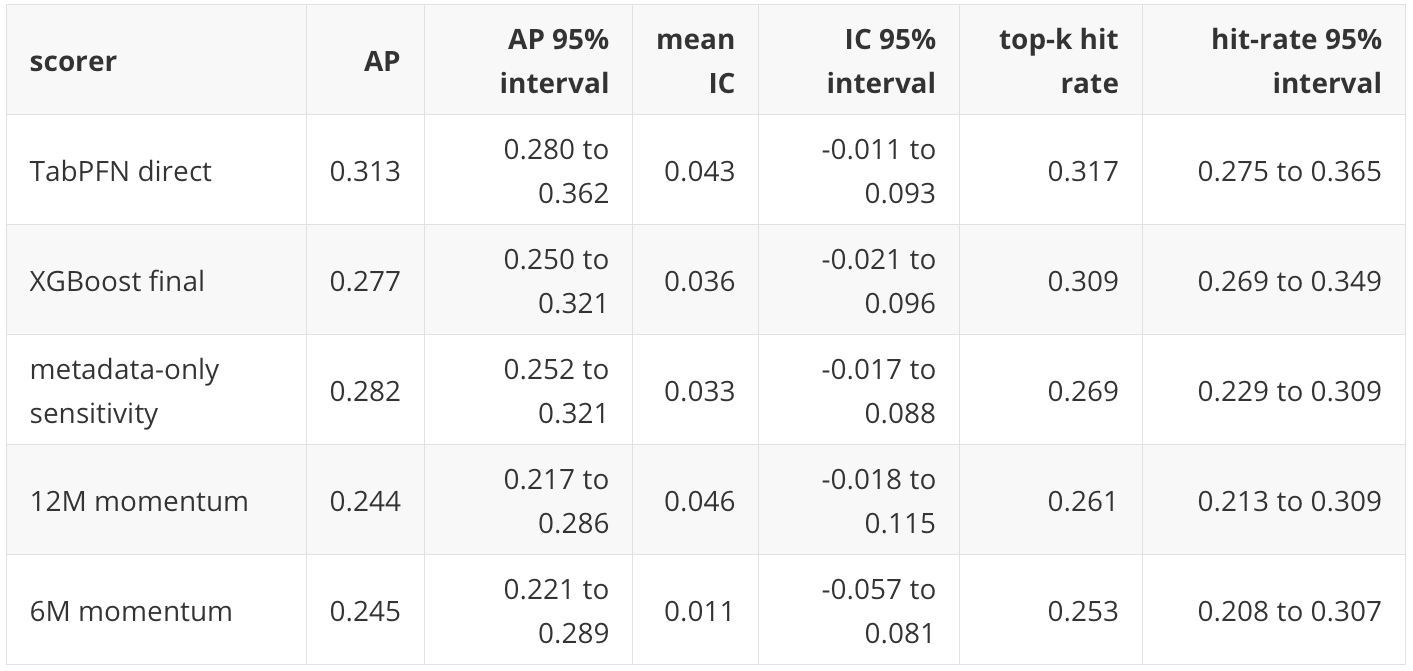
The empirical result changes in an interesting way. In P20, direct TabPFN and TabICL had the strongest row-level Average Precision point estimates, around 0.409 against a 0.333 base rate, while XGBoost had stronger portfolio diagnostic point estimates. In this follow-up, TabICL is not part of the final empirical comparison because the full TabICL run hit RAM limits on Kaggle. Direct TabPFN remains the strongest row-level ranker among the models I completed, with holdout Average Precision of 0.313 against a 0.200 base rate. It also leads the main portfolio diagnostic in this run. XGBoost and the 12-month momentum rule remain serious baselines.
The most important interpretation is not that one model family wins. The useful result is that a more demanding allocation workflow changes the comparison while preserving the central lesson from P20: tabular foundation model scoring can be evaluated inside a realistic supervised ML workflow, but the conclusion depends on ranking quality, monthly cross-sectional behavior, allocation translation, uncertainty, and known limitations.
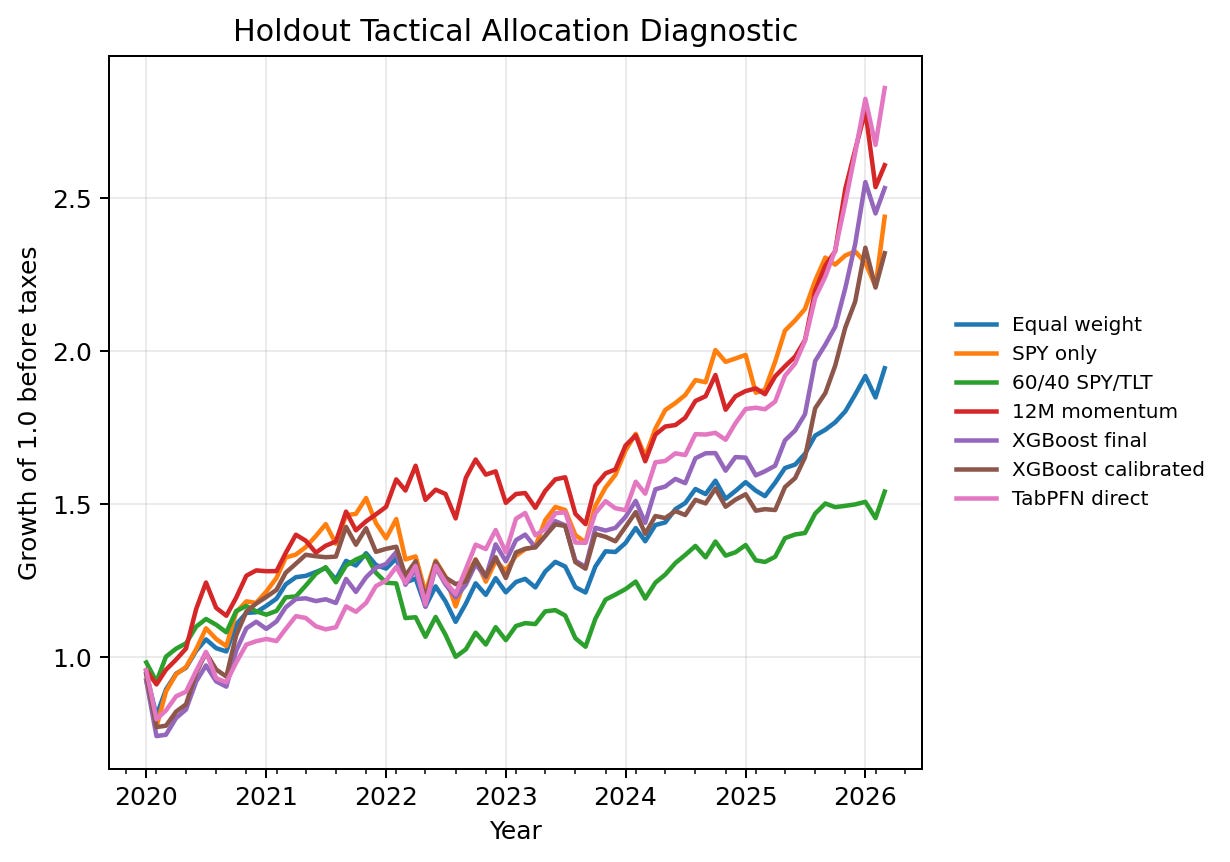
The equity-curve figure gives the high-level result before the tables. TabPFN direct finishes with the highest final equity among the plotted score-driven portfolios, but the path should not be read as a trading recommendation. It is a visual summary of how the monthly score-to-portfolio diagnostic behaved after the same top-five allocation rule and transaction-cost assumption were applied across scorers.
You can find the notebook in my GitHub repository here or you can clone it directly on Kaggle. The results discussed in this post come from the latest notebook version and its generated artifacts.
Minimal notation for this follow-up
P20 gives the full formulation, so I will only restate the notation needed to read this follow-up. Each row is still an asset-month pair \((i,t)\). The feature vector \(x_{i,t}\) contains information available at or before the monthly signal date, and the score \(s_{i,t}\) is used to rank assets within that month. The target \(y_{i,t}\) is 1 when the asset belongs to the next-period top group and 0 otherwise.
The core object is unchanged:
where \(\mathcal{F}_t\) is the information set available at the signal date and \(\phi_i(\cdot)\) is the feature-generation process for asset \(i\). A scorer then produces:
where \(\mathcal{D}_{\text{train}}\) is either the training data for a fitted supervised model or the labelled context for a direct tabular foundation model scorer. This is the only TFM recap needed here. XGBoost learns task-specific parameters from the allocation table. TabPFN uses a pretrained tabular model and the labelled context rows to score query rows:
where \(\theta\) denotes the pretrained TFM parameters, \(x_{\ast}\) is a query row, and \((X_{\text{context}}, y_{\text{context}})\) is the labelled context. The new capability I am exercising is this pretrained in-context scoring mechanism. The old discipline still applies: the target, chronology, leakage controls, baselines, calibration, and portfolio translation remain part of the experiment.
What is new in this experiment
A broader universe and a less coarse target
The P20 universe had 9 ETFs:
SPY, QQQ, IWM, TLT, IEF, GLD, HYG, EEM, VNQ.
This follow-up uses 25 ETFs:
SPY, QQQ, DIA, IWM, EFA, EEM, TLT, IEF, SHY, LQD, HYG, GLD, SLV, DBC, VNQ, IYR, XLB, XLE, XLF, XLI, XLK, XLP, XLU, XLV, XLY.
This adds more US equity style exposure, developed and emerging international equity, rates, credit, commodities, real estate, and US sectors. It is still not a production institutional universe, but it is a more demanding cross-sectional ranking problem than the first notebook.
Let \(N_t\) be the number of available assets in month \(t\). In the holdout period, \(N_t=25\) for the usable months. The target selects \(K=5\) assets. The monthly base rate is therefore approximately:
This matters for Average Precision. In P20, a non-informative scorer had a reference level near 0.333 because three out of nine assets were positive each month. In this post, the reference level is near 0.200. A raw AP number from P20 and a raw AP number from this post should not be compared without remembering that the target is different.
A next-open target convention
P20 used a close-to-close convention. That was easy to audit, but it left an execution caveat: if features are computed at month-end, what price could actually be traded after the signal is formed?
P20 used \(P_{i,t}\) for the adjusted month-end close price. I use a new symbol here because the execution convention changes from close-to-close to open-to-open. Let \(O^+_{i,t+1}\) denote the adjusted first tradable open after signal month \(t\), and let \(O^+_{i,t+2}\) denote the adjusted first tradable open after the next month. The selected one-month target return is:
The label is then:
Here \(\mathbf{1}\{\cdot\}\) is the indicator function: it equals 1 when the condition inside the braces is true and 0 otherwise. The phrase “top \(K\)” means that assets are ranked within the same signal month by the selected forward return convention.
The notebook still saves both close-to-close and next-open returns for audit. This is important because a change in execution convention can change rankings. The goal is not to claim that this is now a complete execution model. It is a more realistic diagnostic convention than the P20 close-to-close target, but it still does not model intraday slippage, bid-ask spreads, order timing, market impact, or data release timing in production detail.
Identity-ablated main features
The P20 notebook included ticker identity indicators and asset-group metadata. That choice was defensible for a fixed-universe allocation exercise, but it raised a good interpretation problem. If the model performs well, is it learning reusable relationships between market-state features and future relative returns, or is it learning persistent differences among named ETFs?
This post makes the main run identity-ablated. If \(z_i\) denotes static identity and metadata features for asset \(i\), the main feature policy is closer to:
The notebook excludes 34 static identity or metadata columns from the main model matrix. The final main feature matrix has 956 model features after retained base features and missingness indicators.
This does not mean identity information is unimportant. In fact, one diagnostic suggests it may be very important. The metadata-only Logistic Regression sensitivity model has a holdout AP of 0.282, which is above the 0.200 base rate and also slightly above the XGBoost final AP of 0.277 in this run. That does not mean metadata-only is a better allocation system. It means persistent asset identity and group structure contain meaningful information in this historical sample. For a practitioner, that is a useful warning: removing identity features makes the main experiment more conservative, but studying identity sensitivity remains part of the interpretation.
Feature sensitivity as a diagnostic, not a full rerun
The notebook compares these feature policies with lightweight CPU Logistic Regression:
full
ticker-ablated
identity-ablated
metadata-only
strict time-series
The important phrase is “lightweight diagnostic.” I did not rerun the full TabPFN and XGBoost workflows for every feature variant because the practical constraint in this iteration was compute time. I had to rerun the notebook several times while working around TabICL memory failures and XGBoost tuning costs; each full attempt took close to two hours, with roughly 1.5 hours spent in the XGBoost tuning part. A full model-by-feature-variant study would be stronger, but that is a separate experiment. The current sensitivity check is useful for inspecting whether feature-family choices matter, but it should not be presented as a complete model-family sensitivity study.
The holdout feature sensitivity table is:
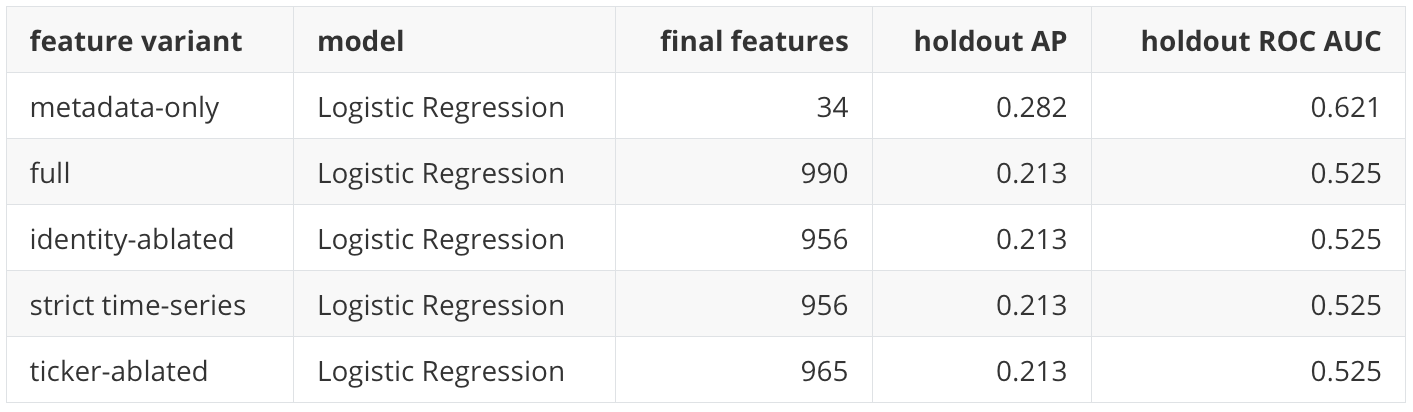
The metadata-only result is the surprising line. It suggests that persistent group and identity information can rank the holdout rows better than a weak linear model using the larger noisy feature set. This is not a reason to abandon time-series features. It is a reason to be careful with interpretation and to treat feature design as part of the scientific result.
Alternative-objective audits
P20 noted that the top-group target was only one possible allocation objective. A production allocator might care about benchmark-relative active return, multi-month horizons, drawdown risk, tax-aware turnover, or risk-adjusted return.
This notebook does not retrain the main models for all of those objectives. Instead, it asks a narrower question: how do the existing one-month scores relate to alternative labels?
For a 3-month or 6-month horizon \(h\), the notebook compounds the selected one-month return convention. In this run, that selected convention is next-open-to-next-open:
where \(m\) indexes the one-month return offset inside the \(h\)-month compounding window. The notebook then assigns a top-\(K\) label using the same cross-sectional ranking idea. It also creates a benchmark-relative label against SPY:
These are audits of the same scores, not new objective-specific training runs. This distinction matters. If a reader wants to know whether TabPFN is best for a six-month allocation target, the correct experiment would retrain and validate on that target. The current notebook asks whether the one-month next-open score contains some information about those alternative outcomes.
Experimental results
Dataset and splits
The final dataset contains 6,059 rows across 243 months and 25 assets. The holdout period contains 1,875 rows across 75 months, from January 2020 through March 2026. The holdout positive rate is exactly 0.200 because the target selects five assets out of twenty-five in each full holdout month.
The chronological split follows the same design logic as P20:
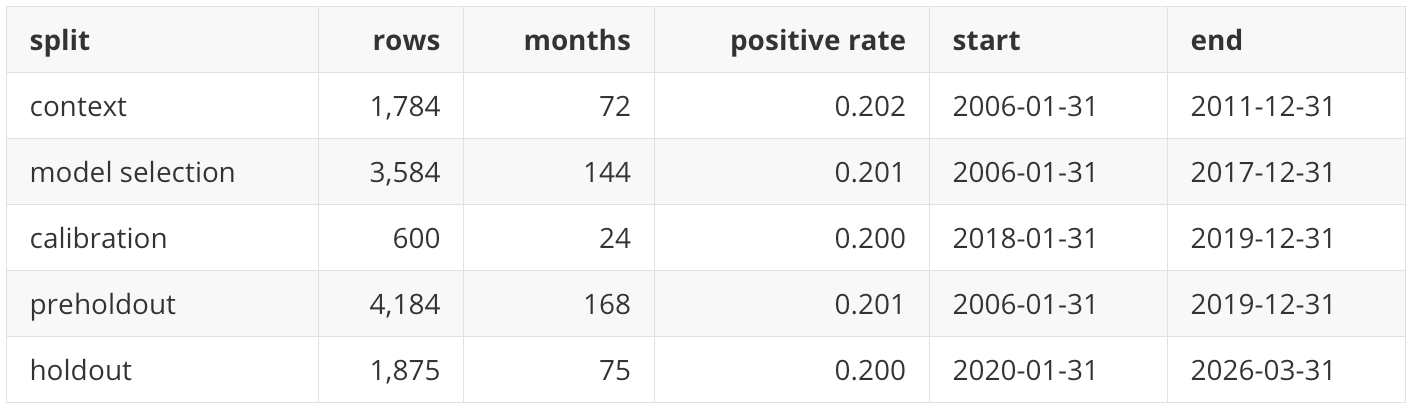
This is a time-ordered split, not a random split.
Row-level classification
P20 used Average Precision, ROC AUC, Brier score, calibration diagnostics, monthly rank diagnostics, and portfolio diagnostics because the target is a top-group ranking label rather than an ordinary balanced classification target. Average Precision summarizes precision-recall ranking quality, ROC AUC summarizes pairwise positive-versus-negative ranking, and Brier score measures squared probability error. I keep those metrics here so the comparison is continuous. The new pieces in this post are not new row-level metrics; they are the lower base-rate target, the next-open target convention, identity-ablated features, feature-policy sensitivity, alternative-objective audits, and the extra portfolio stress diagnostics.
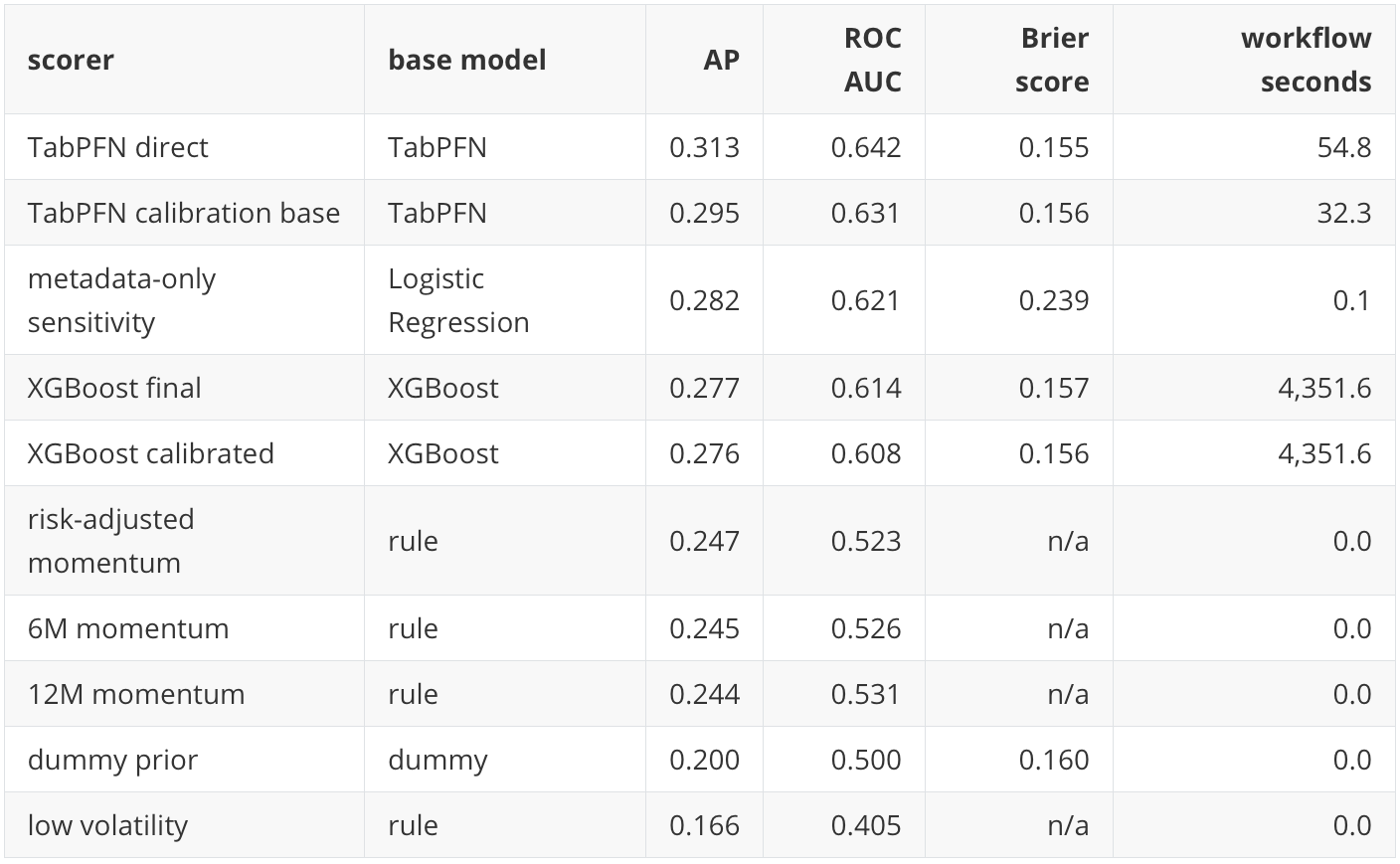
The direct TabPFN scorer has the highest holdout AP and ROC AUC among the completed main models. The comparison with P20 needs care. P20's TabPFN and TabICL AP values were around 0.409, but the base rate was 0.333. Here the TabPFN AP is 0.313, but the base rate is 0.200. On the new, less coarse target, TabPFN is further above the non-informative reference than the raw AP alone would suggest.
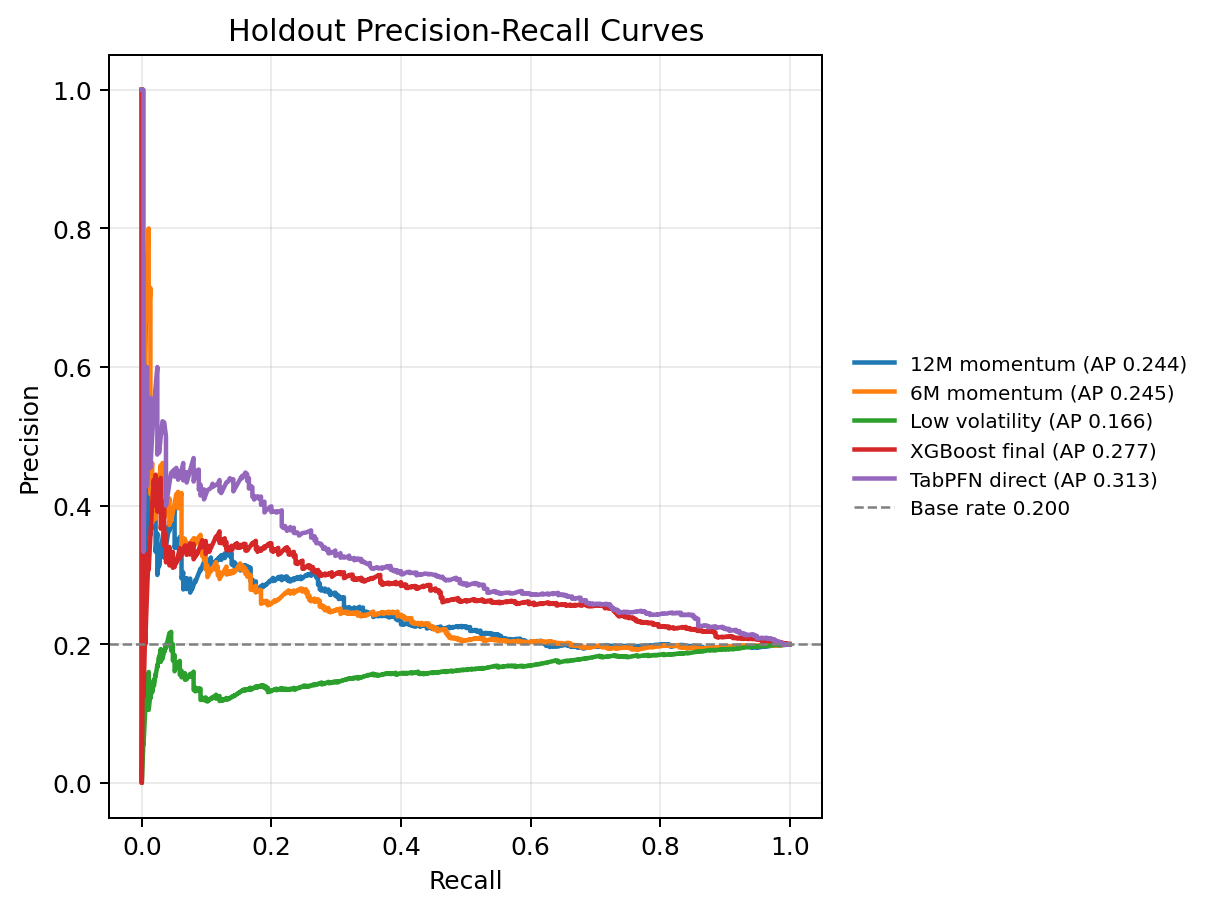
The result is useful for the TFM question because the main TabPFN run is identity-ablated. The model is not being handed ticker identity or asset-group labels in the main feature matrix. It is using the labelled context rows and the time-varying feature table to score holdout asset-month rows.
In the precision-recall plot, the useful comparison is against the lower horizontal base-rate reference. The curves do not need to reach extreme precision to be useful in this setting; they need to stay meaningfully above the 0.200 reference over the part of the ranked list that matters for top-group selection. TabPFN direct does that most clearly among the completed main models.
That does not prove that TabPFN has discovered a stable allocation law. It shows that, in this public-data experiment, direct TabPFN scoring remains competitive after making the target harder, removing static identity features, and changing the execution convention.
Monthly cross-sectional ranking
P20 showed why monthly rank diagnostics matter: TabPFN and TabICL had the strongest row-level AP point estimates, while XGBoost looked stronger in the monthly rank and portfolio views. That same separation of questions matters here. Row-level AP pools all holdout rows together, while allocation is applied month by month. A scorer can have useful pooled AP and still produce a weaker within-month ordering.
For each month \(t\), Spearman information coefficient is:
The mean of \(\rho_t\) across holdout months summarizes whether higher scores tended to align with higher next-open returns within the same monthly cross-section.
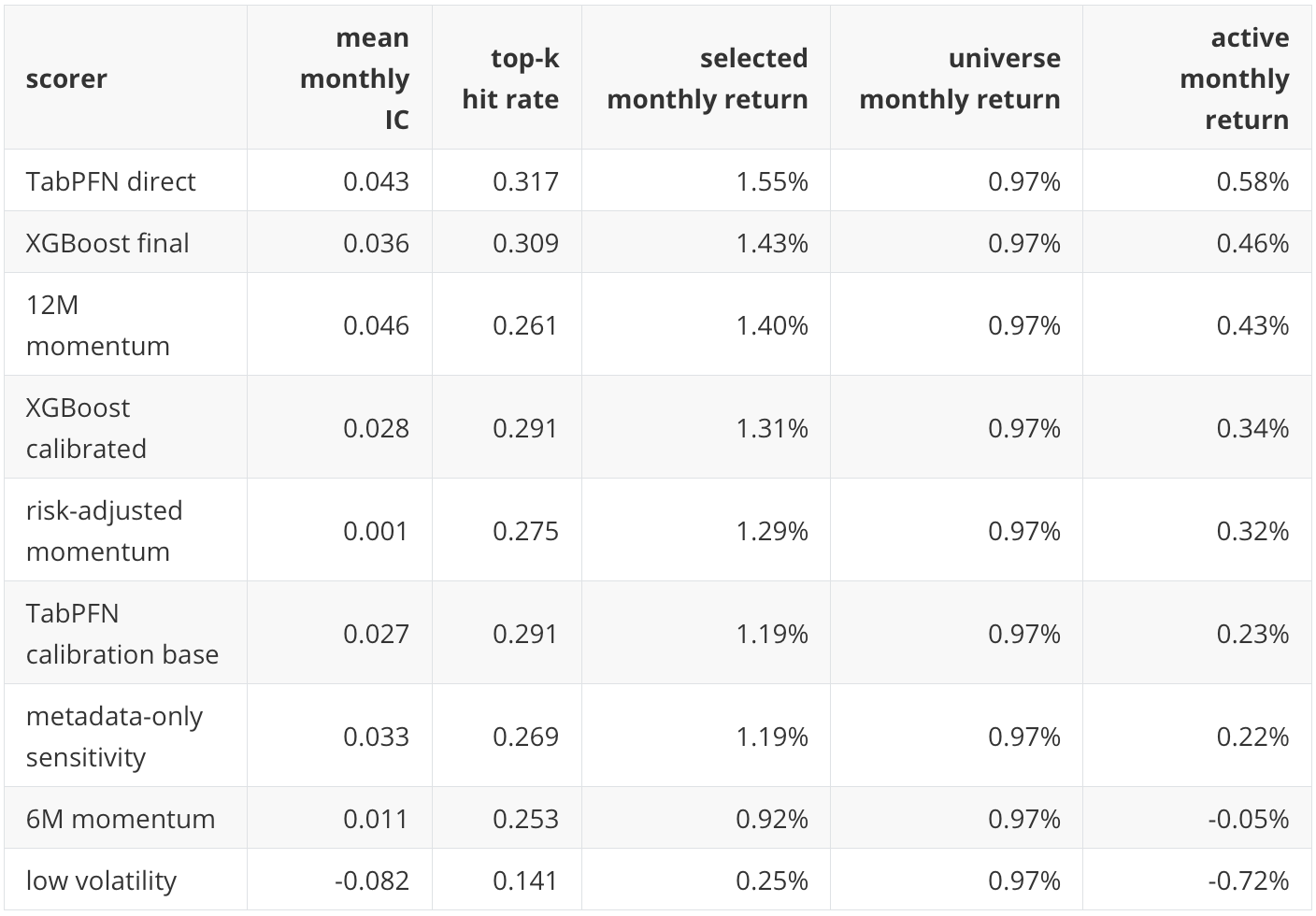
TabPFN direct leads on selected return and active return. XGBoost is close. The 12-month momentum rule has the highest mean IC among these rows, but a lower top-k hit rate and slightly lower selected return. This continues the P20 lesson: mean rank correlation, top-k hit rate, selected return, and portfolio performance are related but not identical.
The low-volatility rule performs poorly in this holdout under this target. That should be read as a period-specific result, not as a general claim against low-volatility investing. The 2020 to 2026 holdout contains a sharp crash, a rapid recovery, an inflation and rates shock, and a strong mega-cap growth period. A defensive rule can look weak under a relative top-five target if the period rewards risk-on or momentum-like exposures.
Portfolio translation
The portfolio diagnostic converts scores into monthly top-five equal-weight portfolios and subtracts a 5 basis point cost per unit of one-way turnover. If \(w_{i,t}\) is the portfolio weight assigned to asset \(i\) after signal month \(t\), the pre-cost diagnostic portfolio return is:
Turnover is:
In these two equations, the summation is over the available assets in the monthly universe. The turnover \(\tau_t\) is one-way turnover: a move from 20 percent in one asset to 0 percent contributes 20 percentage points, and a move from 0 percent to 20 percent in another asset contributes another 20 percentage points.
The net return used in the main portfolio table is:
where \(c=0.0005\) for the 5 basis point transaction-cost assumption.
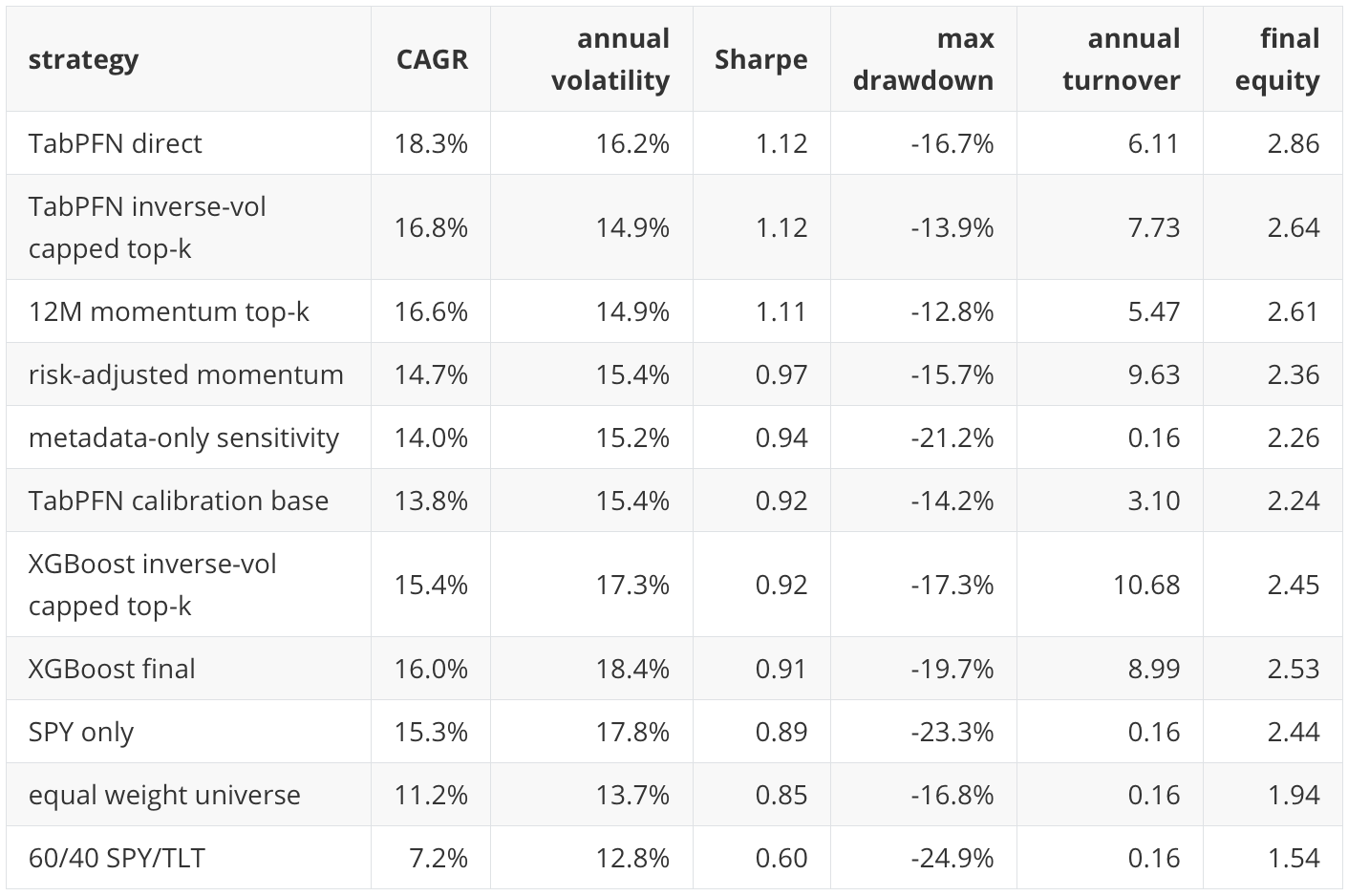
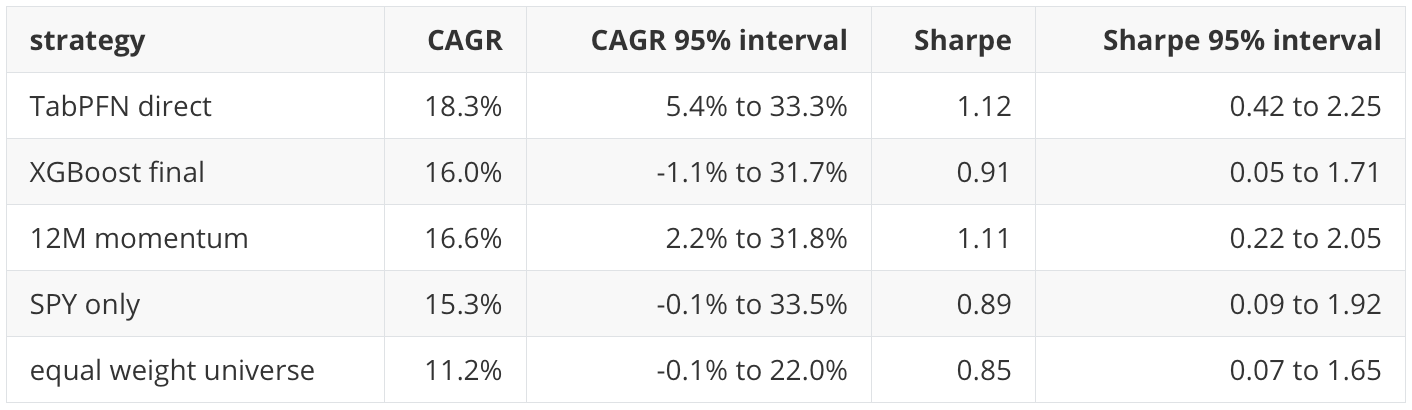
This is the biggest empirical change from P20. In P20, XGBoost had the strongest portfolio diagnostic point estimates. In this follow-up, TabPFN direct leads the main portfolio table by Sharpe and final equity. It also remains ahead after the basic 5 basis point turnover cost.
I do not treat this as a stable trading result. The holdout is one historical path. The confidence intervals are wide. The portfolio is still a simple monthly top-five diagnostic, not a production optimizer. But the result is useful because it shows that the TabPFN row-level advantage is not only a row-level AP artifact in this run. It also survives a simple allocation translation.
Turnover, tax drag, and weight constraints
The notebook adds several stress views that were missing or incomplete in P20.
The turnover-cap diagnostic blends previous weights toward new target weights. With a 50 percent turnover cap, the resulting portfolio can hold more than five assets because old positions decay rather than disappearing immediately. This is not a pure top-five portfolio. It is better described as post-score turnover-smoothed weights.
Selected turnover-cap results:
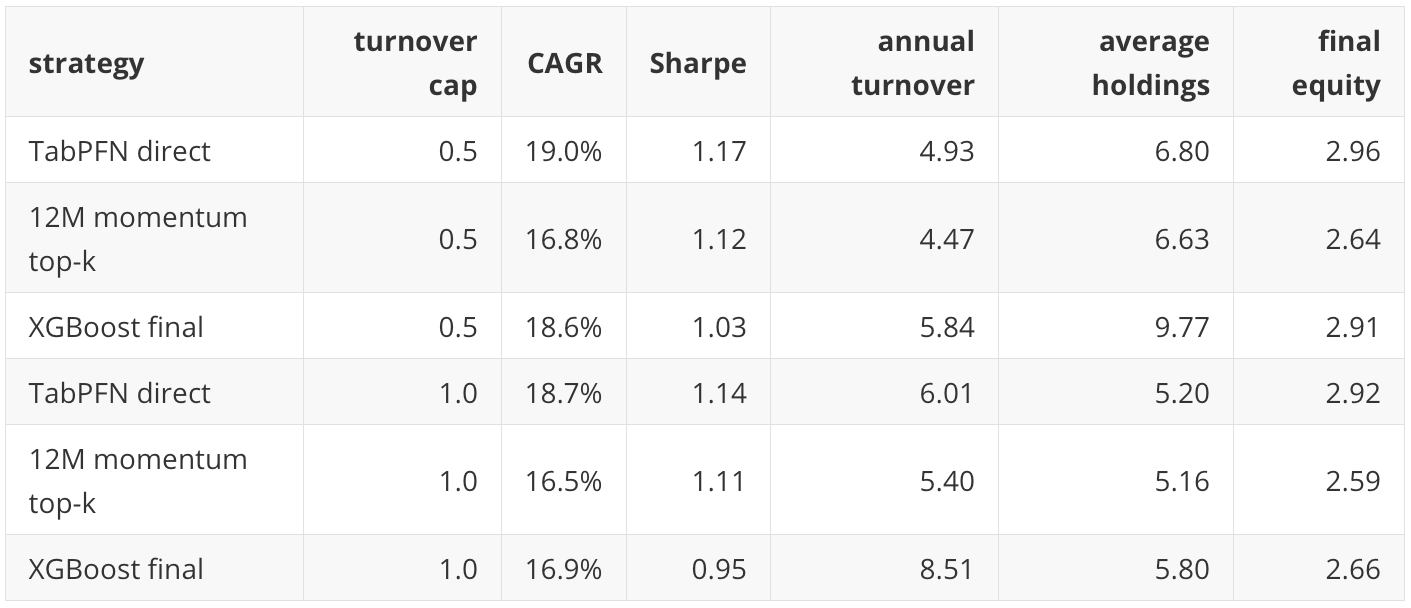
The stress result is favorable for TabPFN and XGBoost, but it changes portfolio meaning. A turnover-smoothed portfolio is not the same object as a strict top-five monthly portfolio. That is why the notebook saves the turnover-cap outputs separately.
The tax-drag sensitivity applies additional drag per unit of turnover. It is not a tax engine. It is a way to ask whether high-turnover strategies are fragile to additional frictions.
For TabPFN direct, CAGR falls from 18.3 percent with no extra tax drag to 14.8 percent with 50 basis points of tax drag per turnover. For XGBoost final, CAGR falls from 16.0 percent to 11.0 percent under the same stress. The larger drop for XGBoost is consistent with its higher annual turnover.
The weight-constraint artifact confirms that the main top-five equal-weight portfolios have 20 percent maximum asset weights and gross leverage of 1.0. It also shows that turnover is not trivial. XGBoost final has 52 months above 50 percent turnover and 17 months above 100 percent turnover. TabPFN direct has 24 months above 50 percent turnover and 5 months above 100 percent turnover. This is one reason portfolio diagnostics are necessary even when row-level AP looks good.
Benchmark-relative diagnostics
The notebook also compares strategy returns against benchmark portfolios such as 60/40 SPY/TLT. Against 60/40, TabPFN direct has annualized active return of about 10.5 percent, tracking error of about 11.8 percent, and information ratio of about 0.89. XGBoost final has annualized active return of about 8.9 percent, tracking error of about 12.5 percent, and information ratio of about 0.71.
These numbers are diagnostics, not mandate-ready active-risk controls. A real benchmark-relative allocation process would usually include explicit tracking-error budgets, sector or asset-class constraints, capacity assumptions, and ex ante risk models. Still, adding the benchmark-relative view is useful because it moves the evaluation closer to how allocation results are often discussed in practice.
Calibration
Calibration remains separate from ranking. If a score is only used to sort assets within a month, a monotonic calibration transform may leave the selected top-five set unchanged. If a score is described as a probability of top-group membership, probability quality matters. ECE means expected calibration error; in the notebook artifact used here, it is computed with 10 quantile bins.
The main holdout calibration view is:
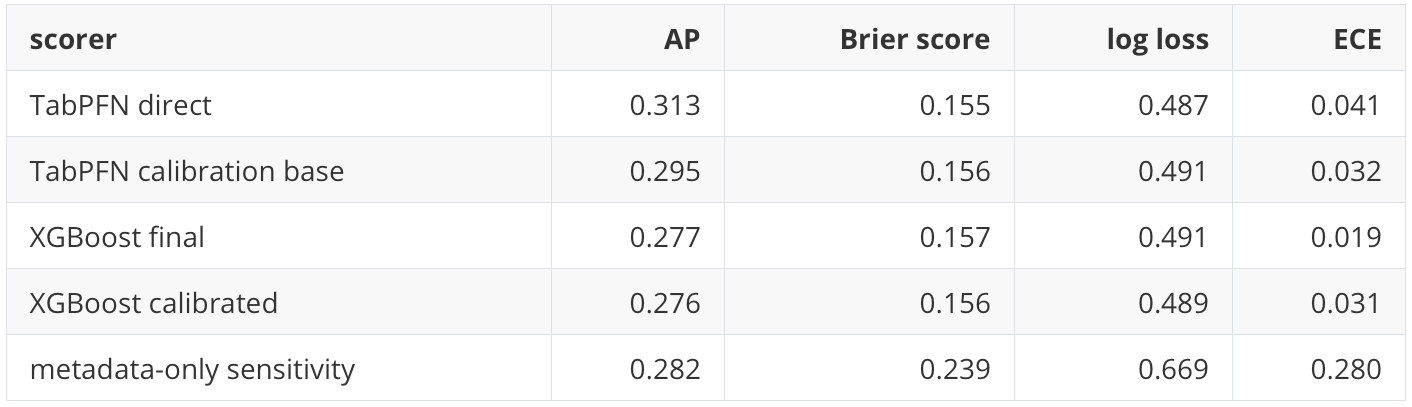
TabPFN direct has the best AP among the listed scorers, while XGBoost final has the lowest expected calibration error among the listed learned scorers. That is not a contradiction. Ranking quality and probability reliability are different properties.
The metadata-only logistic score is a useful caution. Its AP is good, but its Brier score, log loss, and ECE are poor. That means it can rank some positives above negatives while still producing poor probability estimates. A practitioner familiar with supervised ML will recognize this pattern: a model can be directionally useful as a score and still poorly calibrated as a probability model.
Runtime and research cost
Runtime is part of the research result. The direct TabPFN holdout scorer takes about 55 seconds in this run. XGBoost takes about 4,352 seconds because the workflow performs a GPU-accelerated XGBoost model-selection process. This is not a perfectly fair runtime contest because the workflows are doing different things. It is still practically relevant.
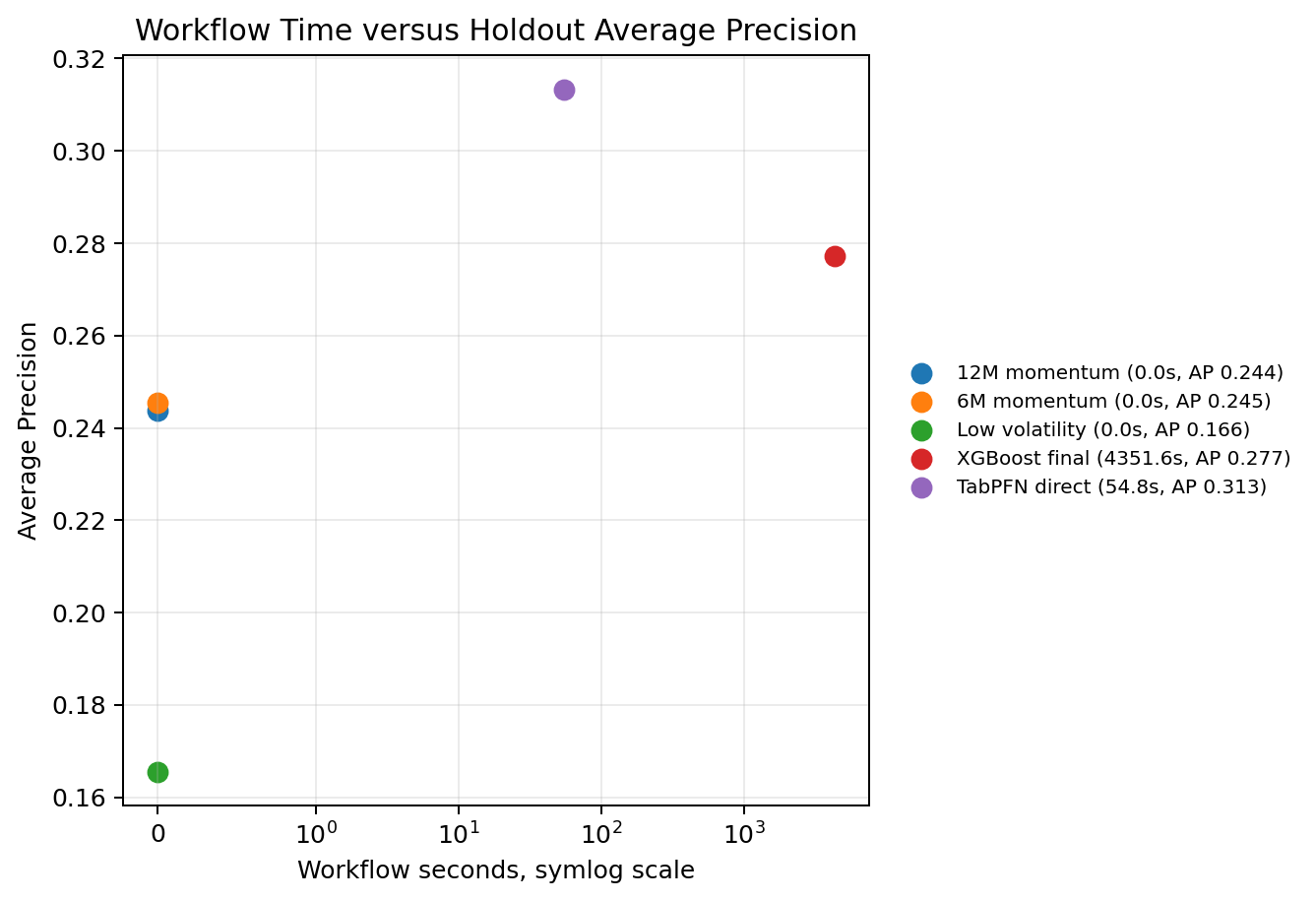
For a practitioner, the TFM capability is attractive when quick direct scoring is valuable. XGBoost remains attractive when task-specific fitting, feature importance workflows, and controlled hyperparameter searches are important. I do not see these as mutually exclusive tools. In a serious research workflow, I would want both kinds of baselines.
Uncertainty
The notebook uses month-block bootstrap intervals. It resamples months rather than individual rows because rows from the same month share the same market environment and are tied together by the cross-sectional top-\(K\) target.
Selected row-level bootstrap intervals:
Selected portfolio bootstrap intervals:
The intervals explain the cautious language. TabPFN has the best point estimates in the main diagnostics, but the uncertainty intervals overlap with strong baselines. This is evidence of competitiveness in one public-data holdout path, not proof of stable superiority.
Known limitations
This is still a public-data research workflow. It uses yfinance, public Cboe VIX history, and public FRED series. That is useful for reproducibility, but it is not equivalent to a licensed point-in-time institutional market data system. Vendor corrections, corporate-action controls, survivorship handling, data release timing, and operational monitoring are outside the scope of this post.
The liquidity, spread, and market-impact proxy artifact should not be interpreted in this run. The notebook created portfolio_liquidity_impact_proxy.csv, but the artifact values are all zero because the underlying dollar-volume and high-low-spread proxy fields were missing. I am leaving the issue documented rather than fixing it today because the main post can stand without that artifact. Any claim about liquidity, spread, or participation should wait for a corrected rerun.
The feature sensitivity section is not a full model-family sensitivity study. It uses Logistic Regression diagnostics to inspect feature-policy effects. A stronger version would rerun TabPFN, XGBoost, and any enabled TFM scorers across all feature variants under the same chronological validation design.
The multi-horizon and benchmark-relative sections are audits of existing one-month scores. They do not retrain the main models for 3-month, 6-month, or benchmark-relative objectives. A proper alternative-objective study would define those labels as the main targets and repeat model selection and validation.
The portfolio diagnostics are not production backtests. They do not include a real execution model, tax lots, mandate constraints, borrow constraints, capacity, market-impact estimation, ex ante risk models, or benchmark-relative optimization. They are useful for testing whether model scores survive simple allocation translation, not for approving live capital.
TabICL is not part of the final empirical comparison in this post. That is an engineering limitation of my current public notebook run, not a statement about TabICL as a model family. The guarded TabICL code path remains in the notebook, but the completed results here should be read as TabPFN, XGBoost, Logistic Regression diagnostics, and deterministic-rule results.
TFM embeddings are still out of scope. This post evaluates direct TabPFN scoring. It does not test whether TabPFN or TabICL embeddings improve a downstream XGBoost, neural ranking, or portfolio optimization workflow.
Finally, my own goal in this series is learning by building. I am using the notebook to make assumptions visible and testable. The claims are intentionally limited to what this public experiment can support.
Conclusion
This follow-up makes the P20 tactical allocation experiment more demanding. The universe grows from 9 to 25 ETFs, the target becomes top 5 of 25, the execution convention changes to next-open-to-next-open, static identity features are removed from the main model matrix, and the portfolio diagnostics become more realistic.
Within this configuration, direct TabPFN produces the strongest completed row-level ranking result: AP 0.313 against a 0.200 base rate. It also leads the main portfolio diagnostic, with 18.3 percent CAGR, 1.12 Sharpe, and final equity of 2.86 over the 2020 to 2026 holdout. XGBoost and 12-month momentum remain competitive. The bootstrap intervals overlap enough that I would not claim stable superiority for any model family.
The most useful conclusion is methodological. A tabular foundation model can be inserted into a supervised financial tabular workflow as a direct scorer, but it still has to be evaluated like any serious model: with chronological splits, leakage checks, baseline rules, calibration diagnostics, uncertainty intervals, feature sensitivity, execution assumptions, and portfolio translation. The newer capability is the pretrained in-context scoring mechanism. The older discipline of supervised ML and financial validation is still necessary.